
I modelli matematici
Previsioni e non profezie
I modelli matematici
Prevedere il futuro con i numeri è possibile?
Dall’inizio di questo anno, i governi di tutto il mondo sono impegnati nella lotta contro un nemico ancora per diversi aspetti sconosciuto: stiamo ovviamente parlando del nuovo coronavirus noto come Sars-Cov-2, causa di una pandemia che sta mietendo migliaia di vittime in tutto il pianeta. Per fronteggiare tale pandemia ogni governo si sta avvalendo del parere di esperti, di comitati scientifici creati ad hoc, virologi, epidemiologi i quali in attesa di avere un'arma efficace contro gli effetti, in alcuni casi letali del virus, continuano a consigliare azioni e protocolli al fine di contenere il più possibile il contagio. Le azioni e i protocolli suggeriti vengono elaborati sulla base dei numerosi dati raccolti dall’inizio della pandemia. E noi cittadini continuiamo ad essere bombardati ogni giorno da cifre, grafici, statistiche e previsioni elaborate sulla base di questi dati. Se fino a qualche settimana fa in Italia si cercava di prevedere quando la diffusione del virus si sarebbe arrestata, ora che le azioni di contenimento del contagio, almeno in Italia, sembrano dare i primi risultati positivi e il virus sembra pian piano scomparire dalle nostre regioni, già si cominciano ad elaborare nuove previsioni sul se e quando il nostro Paese sarà colpito da una seconda ondata di contagi. Noi di Chiedi le prove allora ci chiediamo: ma in generale è davvero così semplice prevedere l'evoluzione di un fenomeno, basandosi anche su pochi dati reali? O ancora, quanti e quali dati sono sufficienti a definire un andamento e poter prevedere gli sviluppi futuri?
Intanto cerchiamo di capire in generale come gli “esperti” intraprendono lo studio di un nuovo fenomeno basandosi esclusivamente sull’analisi dei dati a disposizione. Non è un caso che li chiamiamo “esperti”: ma vedremo più avanti il perchè.
Si parte sempre da una zuppa! (direbbe il maitre del Grand Milan nel film Totò, Peppino e la malafemmina): si, perché all’inizio, quando ci si trova di fronte ad un fenomeno nuovo e di esso si sa ancora troppo poco, i primi dati possono rappresentare una vera e propria “zuppa mista” di numeri che senza una chiave di lettura adeguata quasi mai sono in grado di fornire “informazioni” utili su ciò che si sta cercando di studiare.
I professori della Facoltà di Economia dell’Università Cattolica Giuseppe Arbia e Vincenzo Nardelli in un loro articolo [1] fanno un’importante distinzione tra “dato” e “informazione”: semplificando in poche parole spiegano che “tanti dati non rappresentano necessariamente tante informazioni[...]”. Infatti, lo mostreremo con degli esempi, non conta solo la quantità di dati a disposizione ma anche la qualità.
Dopo questa breve premessa cerchiamo di capire come partendo da pochi dati gli “esperti” elaborano una previsione.
Anche con pochi dati a disposizione la prima cosa che gli scienziati fanno è riportare questi ultimi come punti di un diagramma cartesiano[2], in maniera tale da avere una prima idea di quale relazione esista tra le grandezze fisiche in gioco. Nelle scorse settimane, ad esempio, il diagramma cartesiano più atteso e monitorato da ogni cittadino è stato senza dubbio quello del numero giornaliero di contagiati nella propria regione nella speranza di osservare il tanto desiderato "picco", che avrebbe così determinato l'inizio della fase calante del contagio.
Ma già dai primi giorni di pandemia molti gruppi di studiosi, ricercatori ed esperti, anche se con pochi dati a disposizione (in matematica statistica si parla di training set) hanno effettuato previsioni sulla data di raggiungimento del picco o meglio ancora sulla data in cui in Italia si sarebbero avuti zero nuovi contagi.
Una delle tecniche utilizzate per questo genere di previsioni è quella del Fitting matematico: per dirla in parole semplici è un pò come fare il gioco dell’unisci i puntini, dove però nel caso del fitting matematico non basta ottenere una linea spezzata ma piuttosto si cerca un’unica curva, rappresentata da una relazione matematica, che tocchi più dati reali possibili. Una volta individuata la relazione che meglio si adatta ai dati a disposizione, il gioco è terminato perchè, mediante tale relazione matematica, per “conoscere il futuro”, basta “estrapolare” il punto di nostro interesse al di fuori dell’intervallo di valori noti.
Ma come si individua la curva che meglio si adatta ai dati a disposizione?
La tecnica di fitting più utilizzata è quella dell'interpolazione polinomiale.
Senza entrare troppo nel tecnico, da un punto di vista puramente matematico, l'interpolazione polinomiale consiste nel trovare la funzione polinomiale che meglio si avvicina ai dati a disposizione, in altre parole la curva risultante deve passare accettabilmente vicino a tutti i punti noti. Da un punto di vista grafico e direi più intuitivo, invece, significa "addolcire" gli spigoli della linea spezzata che si ottiene dall'"unisci i puntini".
Recuperare una pallina da tennis con il metodo del fitting
Per comprendere meglio quanto appena detto con qualche termine un pò troppo “matematico” facciamo un esperimento virtuale. Immaginiamo di essere in cortile a giocare a tennis contro il muro e di avere una macchina fotografica al lato del nostro campo da gioco a scattarci decine di foto al secondo, essendo noi enormemente vanitosi. Però probabilmente non pubblicheremo alcuna foto sui social perché dopo pochi rimbalzi lanciamo troppo alto e forte e la pallina passa oltre al muro e nel frattempo non avremo ancora prodotto una posa decente, da degni campioni dell’Australian Open. Poco male, è solo una pallina da tennis, però è l’unica che abbiamo e vorremmo recuperarla per cercare di avere qualche bello scatto da pubblicare. Ma dove la cerchiamo? È finita in strada, nel cortile subito dietro al muro o era abbastanza veloce da finire in quello successivo? Se non fosse un esperimento virtuale compreremo un nuovo set di palline da tennis e riproveremo qualche giorno dopo. Trattandosi invece di un esperimento virtuale ci rendiamo conto che stavamo scattando le foto proprio di lato, e quindi conosciamo la posizione della pallina, istante per istante, ma solo prima del muro. A volerla disegnare schematicamente:
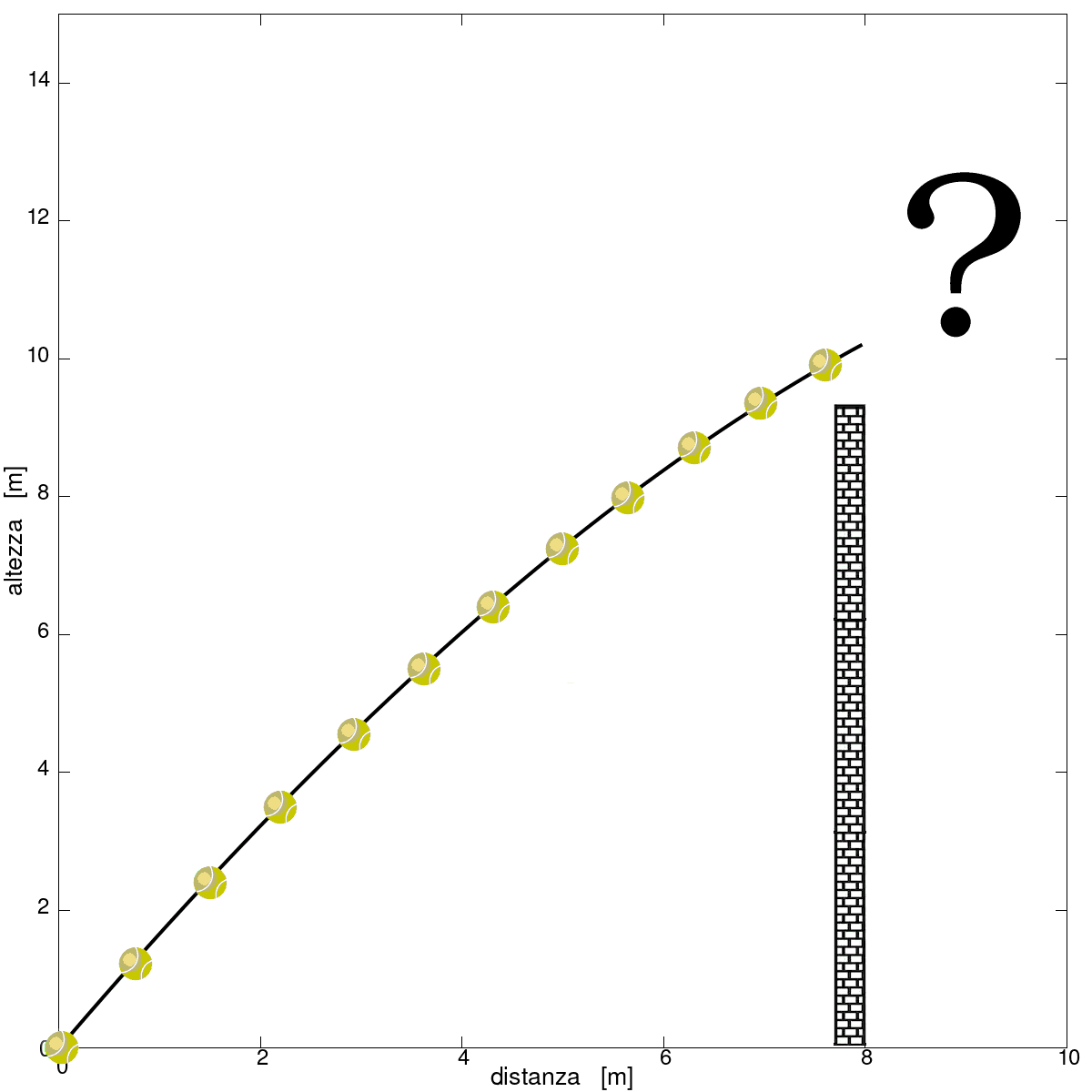
L’altezza iniziale di 0 metri è riferita al punto in cui la pallina lascia la racchetta e certo, trattandosi di un esempio di fantasia, il muro è alto quasi quanto un palazzo e più che una racchettata sembra una cannonata che manda la pallina in orbita. Ma dove andrà a cadere, almeno indicativamente? Lo possiamo scoprire unendo le diverse posizioni della pallina durante l’ultimo balzo con una linea, e continuando la linea nella parte mancante sulla base delle informazioni che già abbiamo. Se sull’asse orizzontale al posto della distanza dal punto di lancio ci fosse stato il tempo avremmo cercato di fare una “previsione” della traiettoria negli istanti futuri. Trattandosi di una pallina da tennis “istanti futuri” significa quei pochi secondi di volo della pallina, ma se invece di una pallina da tennis si considerano processi di durata più lunga “istanti futuri” può voler dire ore, giorni, mesi o anche anni se si pensa alle orbite dei pianeti. Ma la pallina allora? In che cortile la andiamo a cercare? Beh, per prima cosa dobbiamo sapere che genere di curva è quella che descrive la pallina, se sappiamo quello possiamo poi trovare tra le curve di quel tipo quella che si “sovrappone” al pezzo che conosciamo et voilà, possiamo ricostruire la traiettoria della pallina da tennis dietro al muretto. Serve dunque una certa conoscenza della natura del processo che si vuole studiare; ecco perché all'inizio di questo articolo abbiamo parlato di "esperti": in questo caso è noto che la pallina compie un moto parabolico e dunque la traiettoria (non solo nel tempo ma anche nello spazio) è una parabola che ha una funzione y = ax^2 + bx. Si studia alle superiori con il classico esempio della palla di cannone: si tratta quindi di trovare i giusti valori di a e di b e sappiamo dove andare a cercare la pallina che abbiamo perso! Non preoccupiamoci troppo di come trovare questi valori, esistono dei programmi che lo fanno per noi[3], ed ecco dove va la pallina:
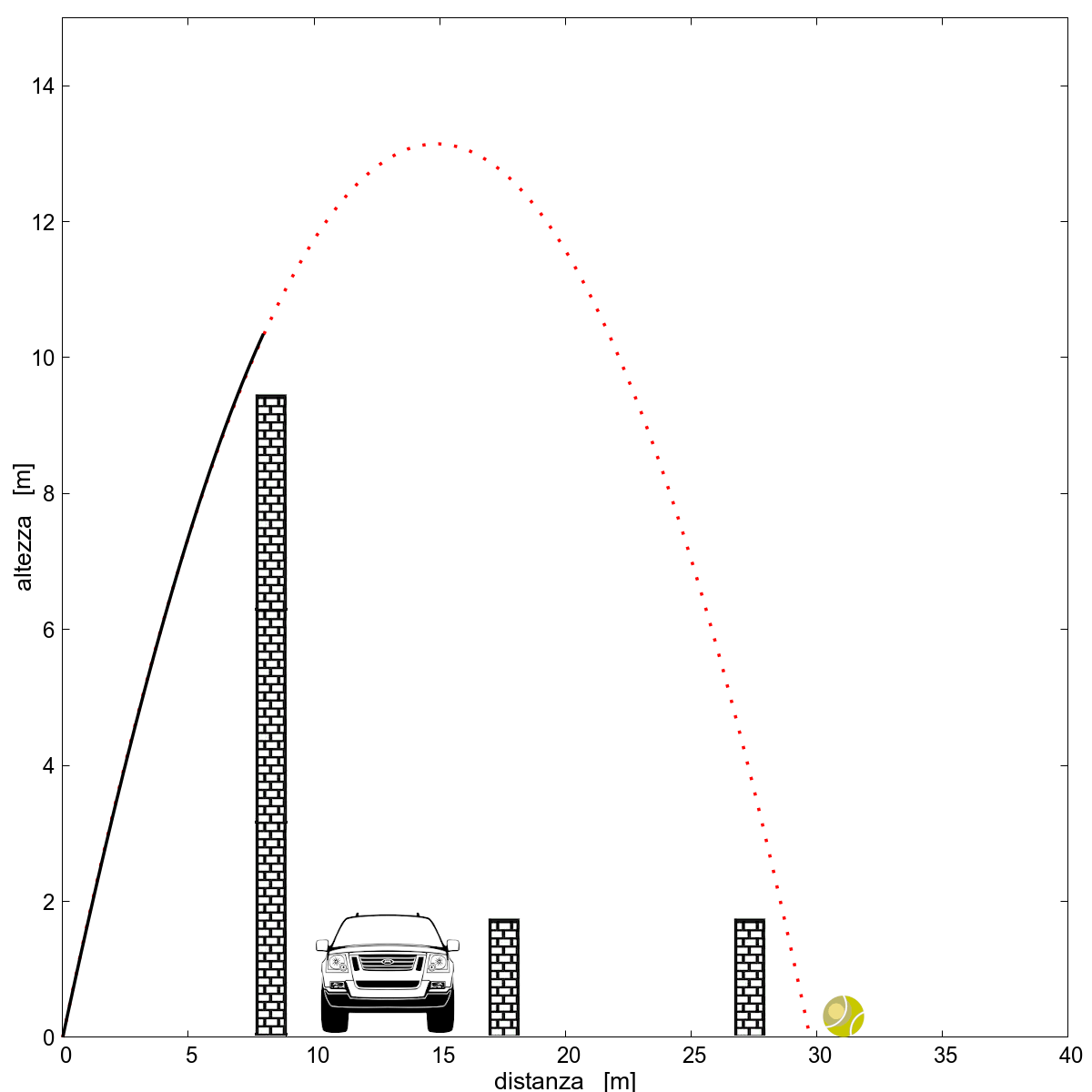
Bello eh? Sapevamo che era una parabola, e non a caso il fit si sovrappone perfettamente alla linea nera che rappresenta quello che abbiamo osservato della pallina, a maggior prova che la pallina segue effettivamente un moto parabolico. La pallina dunque non la troveremo, per fortuna, in mezzo alla strada e nemmeno nel giardino adiacente. Sarà nel cortile dell’altro vicino di casa.
Dopo avere fatto una visita al vicino di casa però ce ne torniamo a mani vuote, un po’ sconfortati perché l’esperimento è fallito, e un po’ perché il vicino si è lamentato e non abbiamo neanche trovato la nostra pallina da tennis. Amareggiati dal fatto che sta scienza, tutto sommato, mica funziona tanto, ne parliamo con il nostro amico ingegnere che, animosamente, ci racconta che - cosa un po’ meno conosciuta del moto parabolico - esiste la legge di Stokes, che descrive le forze di attrito di un corpo in un fluido. Il moto parabolico è bello, semplice e si studia come esempio ideale, ma funziona nel vuoto ed è una buona approssimazione solo in certi casi. Le forze di attrito del fluido aria rallentano un po’ il moto orizzontale della pallina, e anche quello verticale. Oltretutto queste forze sono tanto più intense quanto maggiore è la velocità; l’effetto è che se la pallina dovesse scendere indefinitamente (ad esempio la lanci giù da una montagna) la sua velocità aumenterà fino al punto in cui la forza di gravità viene bilanciata dalle forze di attrito e a quel punto continuerà a cadere con una “velocità di saturazione” costante. Un comportamento ben diverso dal moto parabolico!
Sì, però la parabola descrive bene quei dati!
Questa osservazione ci fa vincere la completa attenzione del nostro amico che dopo un po’ di conti a matita[4] ci invita a provare a “fittare” una formula un po’ diversa: y = a*x + b*log(1-c*x)+d

Ed ecco qua che scopriamo due cose: la prima è che anche quest’altra funzione, di cui ignoriamo il significato, descrive bene i nostri dati iniziali e fornisce delle previsioni molto diverse. La differenza tra la linea rossa e quella blu è che la rossa la facciamo utilizzando un modello che possiamo conoscere se ricordiamo le lezioni di fisica delle superiori, quella blu contiene conoscenze di meccanica a livello universitario. La seconda cosa che scopriamo è che la pallina è finita nell’altro giardino, quello con i dobermann e quindi la lasciamo lì !
Come sempre è tutto più complicato
Riprendendo il precedente esempio dobbiamo riconoscere che si tratti di un esempio un po’ scemo per mostrare come un fit senza una solida conoscenza dei fenomeni in questione potrebbe essere accurato ma avere un pessimo valore predittivo. È utile quando si hanno delle misure ma non si conoscono i parametri specifici e nel caso della pallina ad esempio conosciamo parte della traiettoria ma non abbiamo avuto la possibilità di misurare velocità iniziale, angolo della traiettoria rispetto al suolo e coefficiente di attrito viscoso. Sappiamo però che sono parametri del modello da usare, e quindi possiamo “fittare” il modello e ottenerli indirettamente insieme alla continuazione della traiettoria. Il modello giusto non sempre è banale come questo, derivare queste banalissime equazioni giocattolo richiede conoscenze di matematica avanzata come ad esempio saper risolvere equazioni differenziali. Ed è comunque ancora un giocattolo: ci sono vari modi più o meno realistici (e complessi) per modellizzare l’attrito, ad esempio noi non abbiamo considerato effetti legati alla forma della pallina: può ruotare, e la rotazione rende un lato della pallina “più veloce” rispetto all’altro causando un attrito che non è uniforme su tutta la superficie, questo dà alla traiettoria l’aspetto “a banana” tipico dei tiri “tagliati”. E non parliamo delle deviazioni della forma della pallina causate dalla percussione della racchetta, insomma la realtà è molto complicata, e non possiamo improvvisarci esperti e fare dei fit soltanto perché sappiamo come farli, dando l’idea di poterli utilizzare in modo predittivo.
A questo punto, nel dubbio, utilizzo una funzione complicata! Bel tentativo ma “più complicato” non vuol dire necessariamente “più preciso”. Un modo molto intuitivo per vederlo è tornare a essere più realisti: dai, sul serio pensavate che da alcune fotografie fatte alla pallina si riesca a trovare una traiettoria così pulita, soprattutto con equipaggiamento “fatto in casa”? Più realisticamente parlando ci saranno delle incertezze che renderanno i dati “rumorosi”: un po’ perché le operazioni di misura che ci permettono di “disegnare” la traiettoria della pallina sono affette da incertezze statistiche, un po’ perché la traiettoria stessa può deviare dal modello ideale in modi assolutamente non banali e irregolari nel tempo: ed ecco a cosa ci riferivamo sempre all'inizio con il concetto di qualità dei dati. Morale della favola, se proviamo a determinare la traiettoria finiamo più con un risultato del genere:
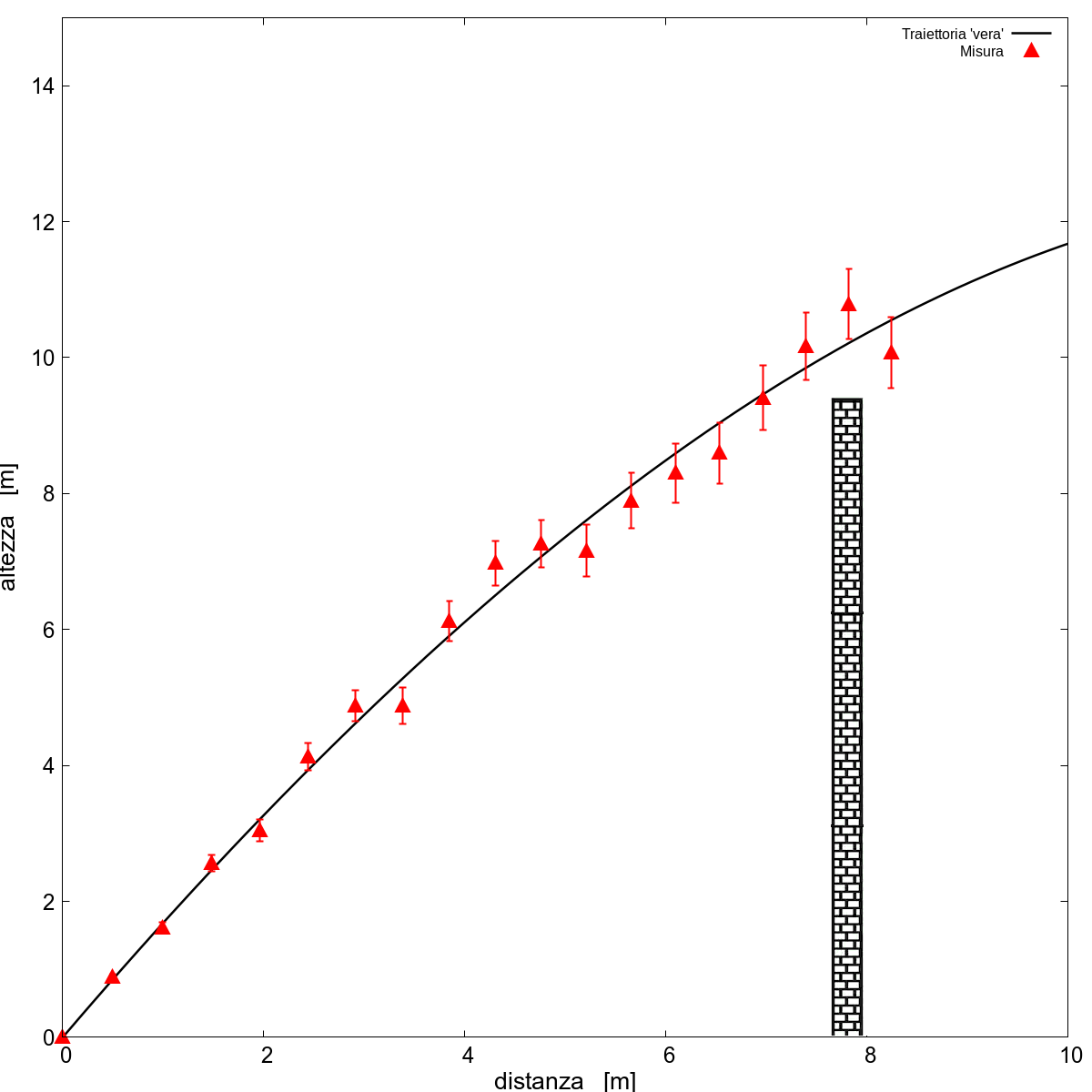
I triangoli sono le posizioni che sono riuscito a determinare, rispetto alla traiettoria che ha realmente fatto (la linea nera, in una situazione reale sarebbe sconosciuta, ma qui immaginiamo di conoscere il risultato giusto) ci sono un po’ di deviazioni. Beh, mica siamo perfetti: ad esempio quando la pallina è lontana dalla fotocamera la prospettiva mi inganna e non riesco a determinare bene la posizione, il risultato è che questi punti “ballano” un po’. Un modo che si usa per quantificare queste deviazioni è quello di rappresentarle con delle “barre di errore” come quelle mostrate nella figura. Non sempre si ha il lusso di averle, e a volte si possono solo stimare grossolanamente, ma il concetto è che più la barra è grande più il dato va preso con le pinze. Va beh, vorrà dire che al programma che produce i fit daremo in pasto - come si usava dire - “quello che passa il convento”.
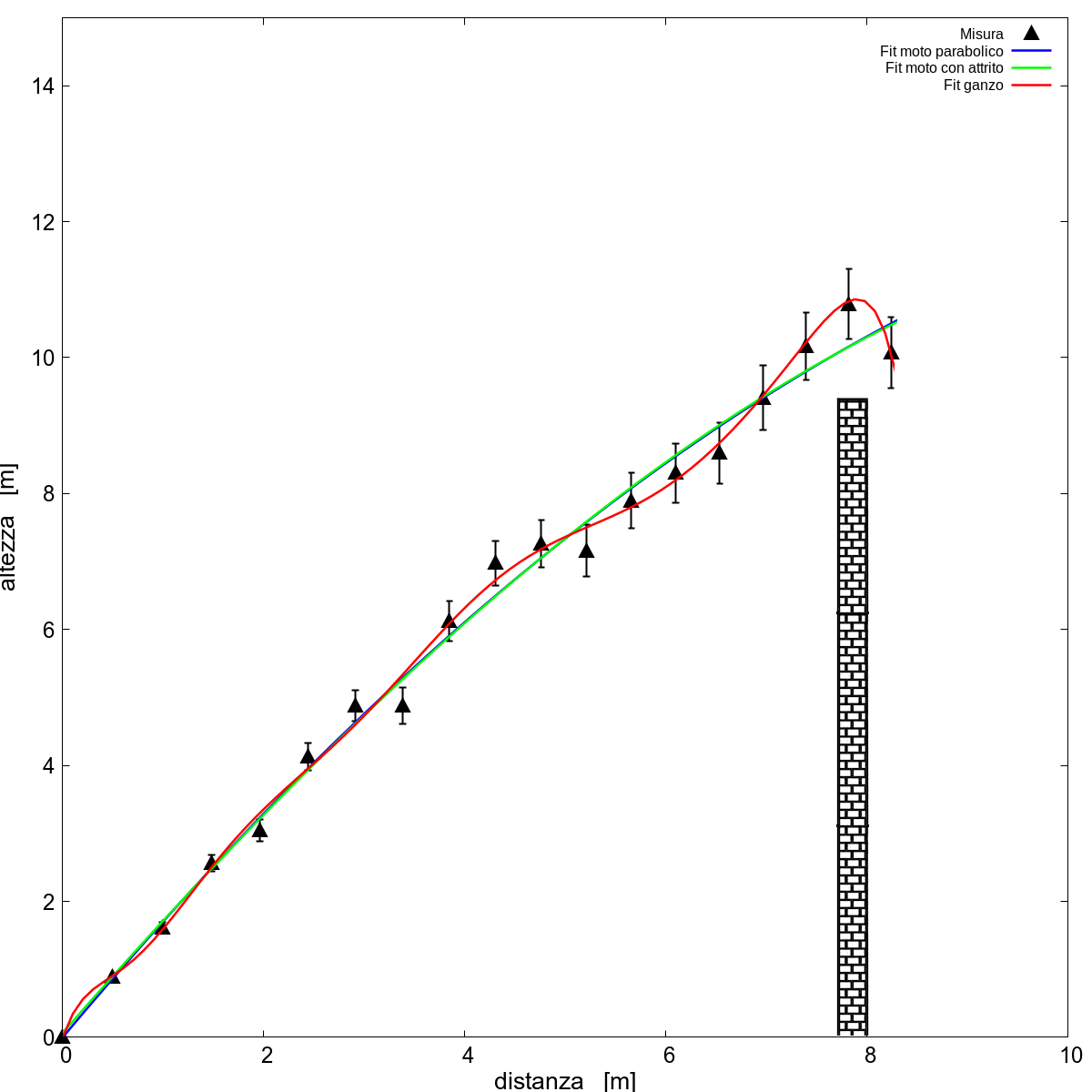
Quando il programma ci fornisce le curve notiamo subito che le formule che avevamo usato in precedenza, la parabola del moto parabolico e la funzione con il logaritmo per il moto parabolico con attrito, non riescono a seguire molto bene i punti. Se invece faccio un minestrone di funzioni matematiche e uso una funzione complicata che contiene sia la parabola che il logaritmo e, ma sì, anche qualcosina di più tipo funzioni cubiche, quartiche e anche oltre riesco a riprodurre molto bene il set di dati. Ma quindi nel dubbio “mettili tutti, il fit riconoscerà quelli giusti”?
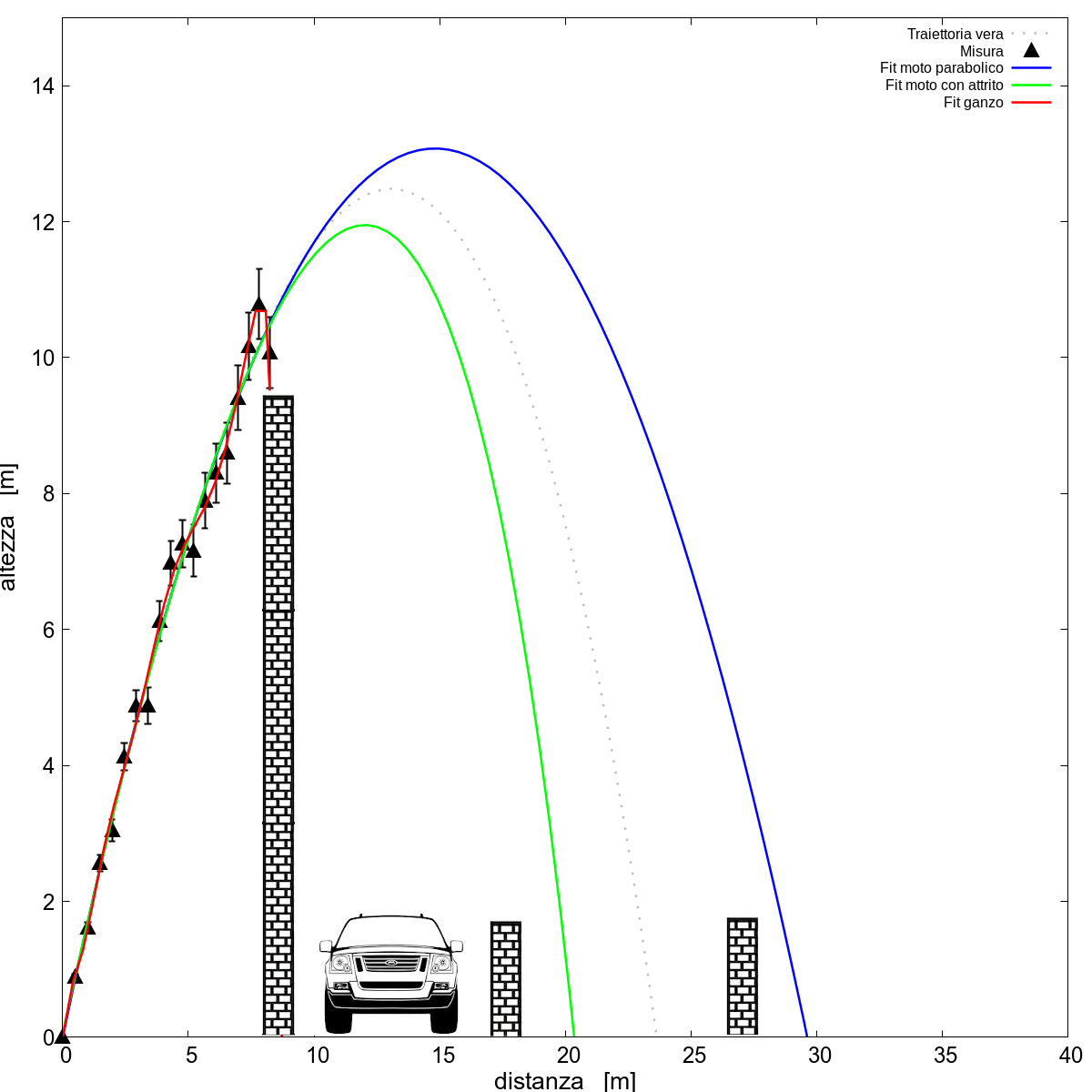
Purtroppo no perché si sta facendo “overfitting”: una funzione “complicata” è in grado di adattarsi meglio ai dati, ma questo vuol dire che se i dati sono rumorosi tutta la “complessità” extra della funzione viene utilizzata per descrivere il rumore, cosa che noi non vogliamo: il rumore è rumore, non contiene nessuna informazione utile ai nostri fini! Infatti se usiamo la funzione “super ganza” per proseguire la traiettoria risulta che la pallina finisce contro il muro! Anche gli altri due fit non forniscono previsioni esatte: per quello parabolico già lo sapevamo - è la funzione sbagliata - ma quello del moto con attrito prima era esattamente sopra la linea tratteggiata invece adesso sottostima la distanza. Ci si deve accontentare di quello che c’è: visto che i nostri dati di partenza avevano delle incertezze, anche le previsioni che facciamo con il modello “giusto” rifletteranno questa incertezza iniziale. Dopotutto stiamo giocando a fare gli scienziati, non i profeti!
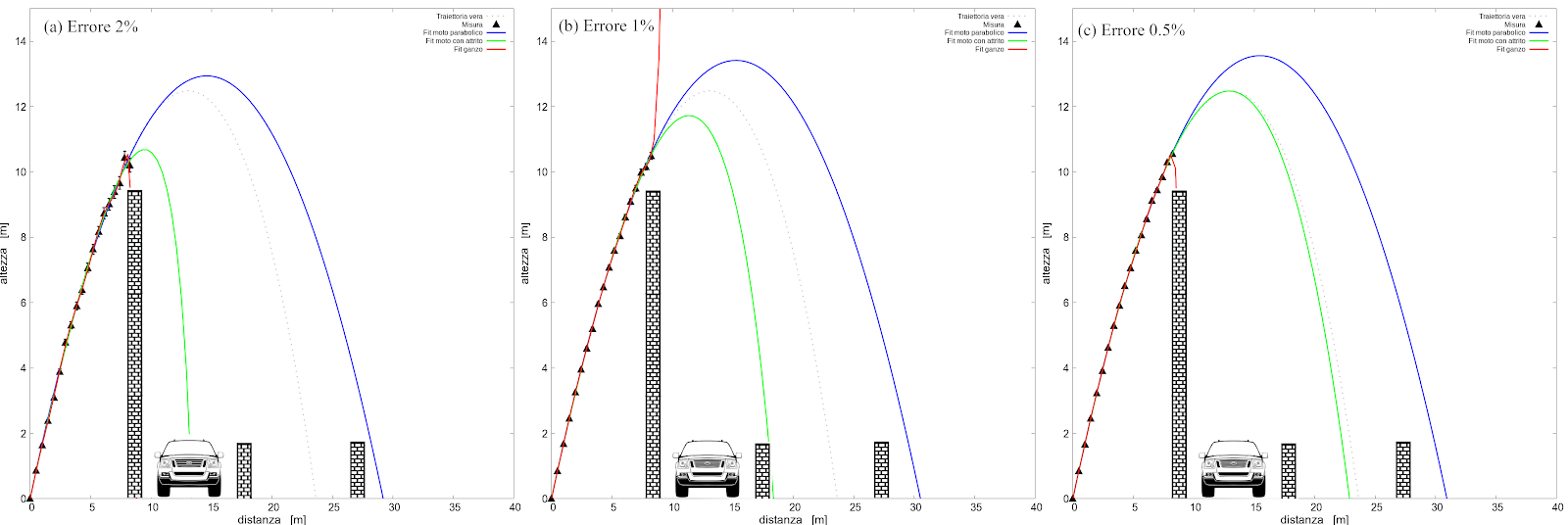
Oltretutto a complicare le cose c'è il fatto che le incertezze sulle previsioni dipendono non solo dalla qualità dei dati ma anche da quanto robusto è il modello rispetto agli errori nei dati. Come linea di guida (ma non è una regola!) modelli più semplici sono anche più robusti, ad esempio il modello della parabola nel nostro caso sbaglia sempre tanto, ma lo fa a prescindere da quanto rumorosi erano i dati di partenza. La linea blu in (a) (b) e (c) nell’immagine qui sopra è un fit parabolico ottenuto partendo da dati con qualità sempre migliore, cioè in altre parole dati sempre più precisi. Bene o male fornisce sempre la stessa previsione sovrastimata. Il modello “giusto” invece con una povera qualità dei dati sbaglia parecchio, prevedendo autisti arrabbiati, ma aumentando la precisione delle misure si avvicina alla curva tratteggiata che rappresenta la traiettoria “vera”. La linea rossa invece è il fit “complicato”, che non ha alcun valore predittivo: a volte prevede che la pallina finisca contro il muro, a volte che finisca da qualche parte nel sistema solare! La robustezza di un modello può essere spiegata in termini matematici, ma c’è anche una spiegazione intuitiva: se i tuoi dati di partenza fanno schifo quello che puoi al massimo dedurre sono le proprietà principali dell’evento che stai studiando, ad esempio nel nostro caso la velocità iniziale e l’angolo di alzo. Le proprietà che producono effetti più piccoli, come ad esempio il coefficiente di attrito sono delle informazioni che si riflettono nei dati di partenza in modo meno vistoso e che viene coperto da una sufficiente incertezza nelle misure.
E allora che validità hanno i modelli predittivi?
Da quanto è emerso dal nostro semplicissimo esperimento virtuale, quindi, sembrerebbe che la capacità predittiva di un modello sia qualcosa di non banale, anzi, a prima vista, sembrerebbe essere più un capriccio arcano degno dei più segreti circoli esoterici che qualcosa di veramente scientifico. E quindi, come molti si sono chiesti, perché fidarsi della scienza? Non è la domanda giusta da porsi: incolpare il metodo è l’analogo anti-scientifico della fiaba della volpe che non riesce ad arrivare all’uva. Delle domande scientificamente più sensate potrebbero essere: qual è l’impatto della qualità dei dati sull’incertezza delle previsioni? C’è un modo di quantificare a-priori questa incertezza? Quali assunzioni nel modello hanno causato l’errore? Hanno un corrispondente fenomenologico o è una semplificazione puramente matematica? È possibile evitarle? Non sono domande semplici, e infatti il valore predittivo di un modello è una questione dibattuta a livello scientifico: valutare esattamente quando prendere con le pinze certe previsioni e quando fidarsi richiede una conoscenza profonda degli aspetti tecnici del modello, della fenomenologia del caso e delle approssimazioni utilizzate. Per fare un altro esempio, consideriamo l’idrogeno, elemento famoso per infilarsi un po’ ovunque, e noto a tutti perché è parte della molecola dell’acqua. Si tratta di un elemento leggero, molto reattivo: infatti se lo vedete in giro da solo è con tutta probabilità in forma molecolare, cioè insieme a un altro idrogeno. Comunque raro vederlo, non tanto perché i nostri occhi gli atomi non li vedono, ma perché si tratta di un gas molto volatile che scappa facilmente dall’atmosfera terrestre. In ogni caso, una tanica di idrogeno molecolare la sappiamo descrivere molto bene tramite modelli statistici che forniscono stime molto precise delle quantità fisiche che vogliamo sapere. Come lo sappiamo? Beh, possiamo farci procurare una tanica di idrogeno (nota: l’idrogeno è un gas MOLTO pericoloso), misurare quello che ci interessa e confrontare con le migliori simulazioni quantistiche che si possono fare. Funzionano benissimo, e infatti ci sono parecchi lavori in letteratura [5], ma qui inizia la parte delicata: se mettiamo l’idrogeno sotto pressione a un certo punto diventerà solido perché quelle povere molecole saranno così “impacchettate” che non avranno più la tipica mobilità di un liquido. Si ritiene che aumentando ulteriormente la pressione, oltre ai limiti raggiungibili in laboratorio, l’idrogeno solido diventi un metallo e a un certo punto diventi addirittura un superconduttore [6]. Perché “si ritiene”? Non possiamo semplicemente prendere le nostre belle simulazioni e vedere cosa succede? No, perché i modelli che abbiamo non sono predittivi a quelle pressioni stellari (e quando diciamo stellari lo intendiamo veramente!): dal punto di vista fisico non conosciamo molto della chimica ad altissime pressioni[7], e sempre nel regime di pressioni alte dal punto di vista matematico quei modelli usano approssimazioni che non funzionano tanto bene. Un fisico teorico queste cose le sa e non si scandalizza se diversi modelli danno diversi risultati, fa parte del mestiere. Sapere quanto fidarsi e cosa si può imparare da modelli approssimati è una parte molto importante del dibattito scientifico che talvolta viene trascurata dall’opinione pubblica. Nelle condizioni giuste certi modelli hanno enormi capacità predittive, come il caso delle onde gravitazionali , previste dal Albert Einstein 100 anni prima della loro osservazione. Senza entrare nel dettaglio, sul sito informativo della collaborazione che le ha misurate per la prima volta nel 2015 si possono consultare i risultati misurati e l’accordo con la previsione ottenuta risolvendo numericamente le equazioni della relatività generale è impressionante.
{kind=link}
Ancora un ultimo esempio di modelli che forniscono previsioni che siamo soliti consultare nella speranza che “c’azzecchino” ci è fornito dalla meteorologia: ci lamentiamo spesso che le previsioni meteo, nonostante siamo abbondantemente nel 2000, non siano precise come ci aspettiamo, rovinando il più delle volte i nostri programmi per il weekend. In realtà, oggi per lo studio dei fenomeni atmosferici abbiamo a disposizione un’enorme quantità di strumenti e tecnologie per misure e analisi dirette come satelliti geostazionari, radar meteorologici, stazioni di rilevamento a terra e molti altri strumenti sofisticati in giro per il pianeta. In supporto a tutta la tecnologia avanzata di cui dispongono oggi i modelli di previsione meteorologica c’è un aspetto, meno noto, ma altrettanto importante: l’enorme quantità di dati raccolti nei secoli intorno ai fenomeni meteorologici che permettono di considerare con i dovuti pesi tutte le possibili variabili in gioco. Nonostante ciò troppo spesso ci capita di raggiungere il lago con in auto il barbecue, il frigorifero portatile colmo di carne da cucinare sul fuoco e di trovarci nel mezzo del diluvio universale, nonostante la nostra app preferita, la sera prima ci aveva consigliato di portare cappellino e t-shirt per il troppo sole che avremmo trovato. Anche in un caso come questo, che certamente suscita sentimenti misti, dire che le previsioni “funzionano benissimo” o “non c’azzeccano mai” è riduttivo e non tiene conto di aspetti più complessi legati all'attendibilità delle previsioni che sono riassunti nella Ref. [8].
Conclusioni, anzi riflessioni finali
In conclusione, quindi, abbiamo visto che, qualsiasi sia il fenomeno che si intende analizzare per poterne prevedere l’evoluzione, anche quando, all’inizio, si dispone di pochi dati, è sempre necessaria una minima conoscenza generale (ad esempio nel caso della pallina da tennis, sapevamo che per via della forza di gravità, il suo sarebbe stato un moto parabolico) al fine di avere la giusta chiave di lettura dei numeri che ci si ritrova a dover elaborare, evitando così di avere solo una inutile “zuppa mista”.
Inoltre nei vari esempi considerati, abbiamo visto che, pur conoscendo la natura del fenomeno, un ruolo fondamentale ai fini dello studio predittivo, è determinato dalla qualità dei dati a disposizione che come abbiamo dimostrato con i nostri esempi, influenza molto i risultati del modello che costruiamo intorno ad essi.
Nel caso in cui compare un fenomeno nuovo, dove quelle che più volte abbiamo citato come “variabili in gioco”, “approssimazioni”, “incertezze” sono tantissime e sconosciute, magari si tratta di un evento anche relativamente raro, che succede in varianti diverse “una volta in cent’anni”, è facile comprendere come qualsiasi previsione, algoritmo o modello possa dare risultati il cui valore predittivo può essere deludente per l’opinione pubblica. La scienza che si fa su ciò che è ancora sconosciuto, ovviamente va intesa come esplorazione e in quanto esplorazione non si ha alcuna idea di dove ci possa portare. Tant’è che se tutto il processo di ricerca avviene senza intoppi, e i modelli di previsione risultano essere corretti sin da subito, molto probabilmente vuol dire che ci si trova di fronte a qualcosa che tanto innovativo non è. D’altro canto modelli che non funzionano o risultati inattesi dall’esterno possono risultare all’opinione pubblica alquanto “deludenti” ma tutt’altro, consentono di disegnare limiti sempre più precisi nel percorso di conoscenza di un nuovo fenomeno, in modo tale da poterlo caratterizzare e infine descrivere accuratamente.
[1] “I dati non parlano da soli: l’epoca del Coronavirus smaschera l’inganno dell’algoritmo-onnipotente e rivaluta il metodo scientifico” - da: Giustizia insieme - ISBN 978-88-548-2217-7 ISSN: 2036-5993
[2] o una rappresentazione grafica più opportuna. In ogni caso si tratta di un’operazione non del tutto banale se le variabili in gioco sono molteplici e serve ricorrere a tecniche di “riduzione dimensionale” - per approfondimenti: “Dimensionality reduction” da Wikipedia.
[3] Ad esempio il modulo Python Scipy, o il programma di visualizzazione gnuplot.
[4] È un esperimento virtuale, i conti sarebbero molto piu’ lunghi e nella realtà gli avremmo detto “sì ok, ci sentiamo domani”.
[5] Phys. Rev. B 70(193411); Eur. Phys. J. D56, 353(2010); J. Chem. Phys. 143, 194302 (2015);Phys. Rev. A 74, 025201(2006).
[6] Un superconduttore è un materiale con proprietà magnetiche molto peculiari. La conseguenza più famosa di queste proprietà è che può far passare corrente elettrica senza opporre resistenza. Insomma: se lo si volesse usare come resistenza elettrica in una stufa non scalderebbe niente! L’ipotesi originale dell’idrogeno superconduttivo: Phys. Rev. Lett. 21, 1748(1968). Qui una rassegna a taglio più divulgativo.
[7] Ulteriori approfondimenti qui
[8] L'affidabilità delle previsioni meteo oggi di Federico Grazzini - dalla rivista ECOSCIENZA n°4/2012 dell’ARPA Emilia Romagna